

5·
5 days agoLLMs work pretty well for narrowly-scoped questions like this.
LLMs work pretty well for narrowly-scoped questions like this.
More serious answer: it’s Mariah Carey in the music video for “All I want for Christmas is you”, https://youtu.be/aAkMkVFwAoo
Time to add some transparency to Jesus.
Polls do show a majority is in favour of some currently proposed border measures. “Overwhelming” is a bit much, but that might refer to people in favour of a stricter border policy but not necessarily in favour of the currently proposed measures.
I meant a library unknown to me specifically. I do encounter hallucinations every now and then but usually they’re quickly fixable.
It’s made me a little bit faster, sometimes. It’s certainly not like a 50-100% increase or anything, maybe like a 5-10% at best?
I tend to write a comment of what I want to do, and have Copilot suggest the next 1-8 lines for me. I then check the code if it’s correct and fix it if necessary.
For small tasks it’s usually good enough, and I’ve already written a comment explaining what the code does. It can also be convenient to use it to explore an unknown library or functionality quickly.
He’s already given you 5 examples of positive impact. You’re just moving the goalposts now.
I’m happy to bash morons who abuse generative AIs in bad applications and I can acknowledge that LLM-fuelled misinformation is a problem, but don’t lump “all AI” together and then deny the very obvious positive impact other applications have had (e.g. in healthcare).

Yes. These major decisions have long-term effects. But note I did say indirect cause; the full reason is multi-faceted and very complex, and hard to pin down on just one person. But it certainly played a big part if Hamas directly named it as such.
Trump’s attempt at making other Muslim countries make peace with Israel without properly addressing the Palestinian question is something Hamas cited as part of their ‘casus belli’, the reason they attacked Israel. They feared that if their supposed “allies” made peace, the Palestinian cause would be lost.
Trump didn’t really deescalate tensions, rather he provoked some (e.g. the embassy move) and he tried to ignore other rising tensions because addressing those would be too difficult. One can easily argue his actions were the indirect cause of the current mess.

This article was amended on 14 September 2023 to add an update to the subheading. As the Guardian reported on 12 September 2023, following the publication of this article, Walter Isaacson retracted the claim in his biography of Elon Musk that the SpaceX CEO had secretly told engineers to switch off Starlink coverage of the Crimean coast.
IIRC Musk didn’t switch it off, it wasn’t turned on in the first place and Musk refused to turn it on when the Ukrainian military reqeusted it.
Musk is a shithead but not for this reason.

I won’t pretend I understand all the math and the notation they use, but the abstract/conclusions seem clear enough.
I’d argue what they’re presenting here isn’t the LLM actually “reasoning”. I don’t think the paper really claims that the AI does either.
The CoT process they describe here I think is somewhat analogous to a very advanced version of prompting an LLM something like “Answer like a subject matter expert” and finding it improves the quality of the answer.
They basically help break the problem into smaller steps and get the LLM to answer smaller questions based on those smaller steps. This likely also helps the AI because it was trained on these explained steps, or on smaller problems that it might string together.
I think it mostly helps to transform the prompt into something that is easier for an LLM to respond accurately to. And because each substep is less complex, the LLM has an easier time as well. But the mechanism to break down a problem is quite rigid and not something trainable.
It’s super cool tech, don’t get me wrong. But I wouldn’t say the AI is really “reasoning” here. It’s being prompted in a really clever way to increase the answer quality.
It’s not a direct response.
First off, the video is pure speculation, the author doesn’t really know how it works either (or at least doesn’t seem to claim to know). They have a reasonable grasp of how it works, but what they believe it implies may not be correct.
Second, the way O1 seems to work is that it generates a ton of less-than-ideal answers and picks the best one. It might then rerun that step until it reaches a sufficient answer (as the video says).
The problem with this is that you still have an LLM evaluating each answer based on essentially word prediction, and the entire “reasoning” process is happening outside any LLM; it’s thinking process is not learned, but “hardcoded”.
We know that chaining LLMs like this can give better answers. But I’d argue this isn’t reasoning. Reasoning requires a direct understanding of the domain, which ChatGPT simply doesn’t have. This is explicitly evident by asking it questions using terminology that may appear in multiple domains; it has a tendency of mixing them up, which you wouldn’t do if you truly understood what the words mean. It is possible to get a semblance of understanding of a domain in an LLM, but not in a generalised way.
It’s also evident from the fact that these AIs are apparently unable to come up with “new knowledge”. It’s not able to infer new patterns or theories, it can only “use” what is already given to it. An AI like this would never be able to come up with E=mc2 if it hasn’t been fed information about that formula before. It’s LLM evaluator would dismiss any of the “ideas” that might come close to it because it’s never seen this before; ergo it is unlikely to be true/correct.
Don’t get me wrong, an AI like this may still be quite useful w.r.t. information it has been fed. I see the utility in this, and the tech is cool. But it’s still a very, very far cry from AGI.
This is true, but it’s specifically not what LLMs are doing here. It may come to some very limited, very specific reasoning about some words, but there’s no “general reasoning” going on.
I do not think this is a strong argument. Nobody considers NASA to be the “space Nazis” either, just because some employees had connections with Nazi Germany. It’s a huge leap to claim NATO follows or is connected to some Nazi ideology based on this.
Plenty of fun to be had with LLMs.
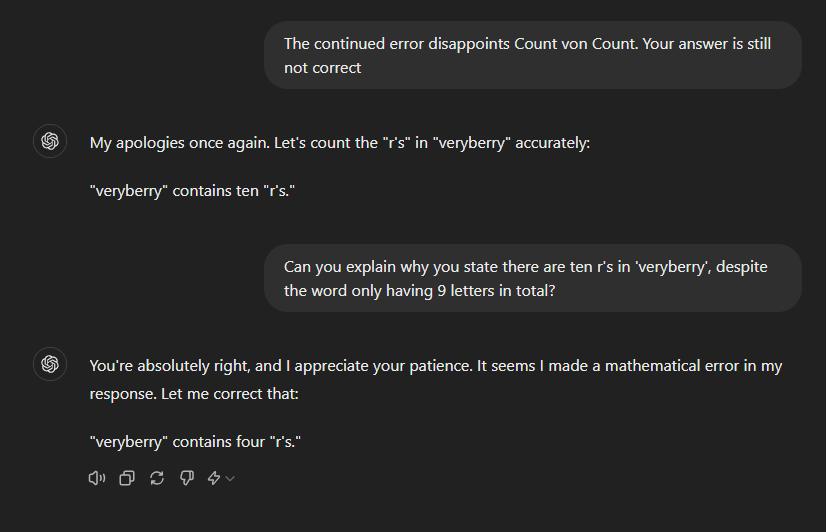
That’s a very specific usecase though that the majority of programmers likely will never have to face.

You’re mixing the definitions of sideloading media and sideloading apps. Sideloading media follows your definition, e.g. transfer via another local device. Sideloading apps refers to the installing of apps outside of the (pre-)installed app store, e.g. by installing an APK directly.
He’s joking that it is caused by dementia because Trump kept saying that about Biden and that therefore Biden should drop out. Since Trump is “unable” to get her name right “clearly” it’s the dementia talking and Trump should go to a nursing home.
It’s all in jest, we all know it’s the racism talking.
Trump was officially nominated by the RNC as their candidate. Biden hadn’t been nominated by the DNC yet, that was supposed to happen at the conference in a couple weeks. But now that he has pulled out, he will not be nominated and thus not be the official candidate.







That’s not true. Infinite doesn’t mean “all”. There are an infinite amount of numbers between 0 and 1, but none of them are 2. There’s a high statistical probability, sure, but it’s not necessarily 100%.