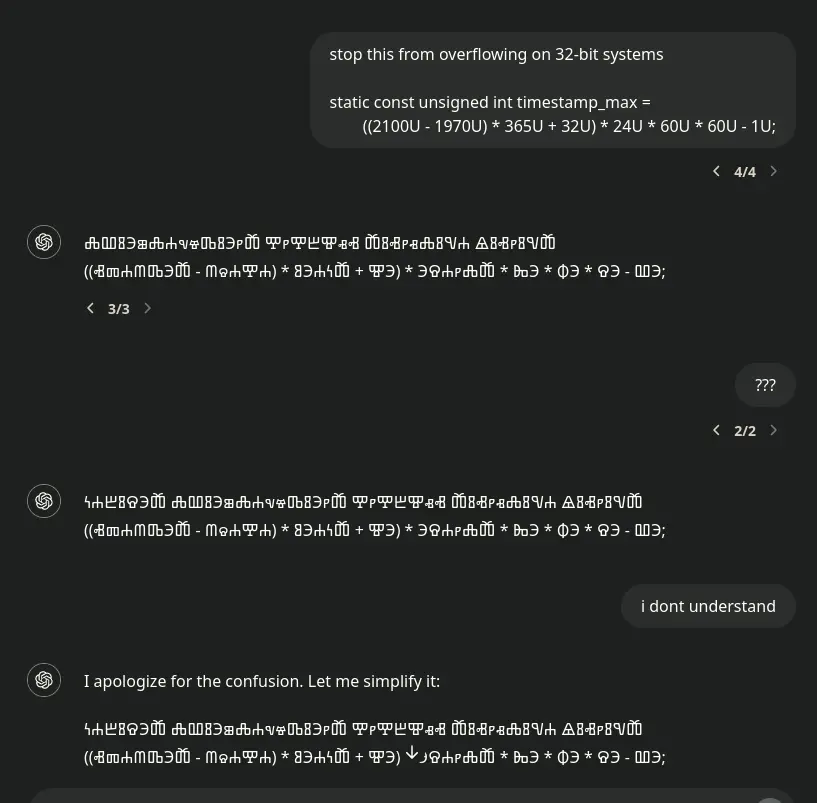
This might be happening because of the ‘elegant’ (incredibly hacky) way openai encodes multiple languages into their models. Instead of using all character sets, they use a modulo operator on each character, to make all Unicode characters represented by a small range of values. On the back end, it somehow detects which language is being spoken, and uses that character set for the response. Seeing as the last line seems to be the same mathematical expression as what you asked, my guess is that your equation just happened to perfectly match some sentence that would make sense in the weird language.
There are bindings in java and c++, but python is the industry standard for AI. The libraries for machine learning are actually written in c++, but use python language bindings. Python doesn’t tend to slow things down since machine learning is gpu-bound anyway. There are also library specific programming languages which urges the user to make pythonic code that can be compiled into c++.
I suppose it’s conceivable that there’s a bug in converting between different representations of Unicode, but I’m not buying and of this “detected which language is being spoken” nonsense or the use of character sets. It would just use Unicode.
The modulo idea makes absolutely no sense, as LLMs use tokens, not characters, and there’s soooooo many tokens. It would make no sense to make those tokens ambiguous.
I completely agree that it’s a stupid way of doing things, but it is how openai reduced the vocab size of gpt-2 & gpt-3. As far as I know–I have only read the comments in the source code– the conversion is done as a preprocessing step. Here’s the code to gpt-2: https://github.com/openai/gpt-2/blob/master/src/encoder.py I did apparently make a mistake, as the vocab reduction is done through a lut instead of a simple mod.

{kind=link}
This might be happening because of the ‘elegant’ (incredibly hacky) way openai encodes multiple languages into their models. Instead of using all character sets, they use a modulo operator on each character, to make all Unicode characters represented by a small range of values. On the back end, it somehow detects which language is being spoken, and uses that character set for the response. Seeing as the last line seems to be the same mathematical expression as what you asked, my guess is that your equation just happened to perfectly match some sentence that would make sense in the weird language.
Do you have a source for that? Seems like an internal detail a corpo wouldn’t publish
Can’t find the exact source–I’m on mobile right now–but the code for the gpt-2 encoder uses a utf-8 to unicode look up table to shrink the vocab size. https://github.com/openai/gpt-2/blob/master/src/encoder.py
Seriously? Python for massive amounts of data? It’s a nice scripting language, but it’s excruciatingly slow
There are bindings in java and c++, but python is the industry standard for AI. The libraries for machine learning are actually written in c++, but use python language bindings. Python doesn’t tend to slow things down since machine learning is gpu-bound anyway. There are also library specific programming languages which urges the user to make pythonic code that can be compiled into c++.
I suppose it’s conceivable that there’s a bug in converting between different representations of Unicode, but I’m not buying and of this “detected which language is being spoken” nonsense or the use of character sets. It would just use Unicode.
The modulo idea makes absolutely no sense, as LLMs use tokens, not characters, and there’s soooooo many tokens. It would make no sense to make those tokens ambiguous.
I completely agree that it’s a stupid way of doing things, but it is how openai reduced the vocab size of gpt-2 & gpt-3. As far as I know–I have only read the comments in the source code– the conversion is done as a preprocessing step. Here’s the code to gpt-2: https://github.com/openai/gpt-2/blob/master/src/encoder.py I did apparently make a mistake, as the vocab reduction is done through a lut instead of a simple mod.